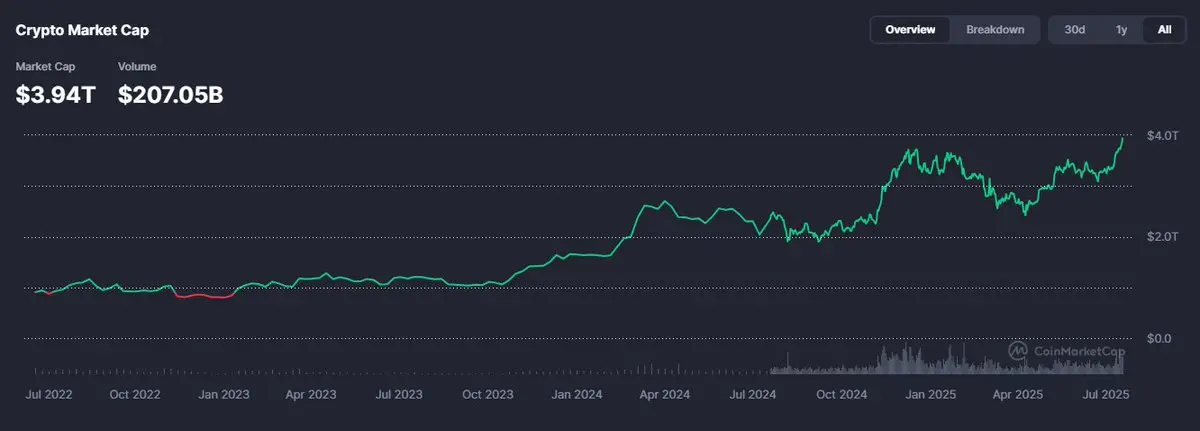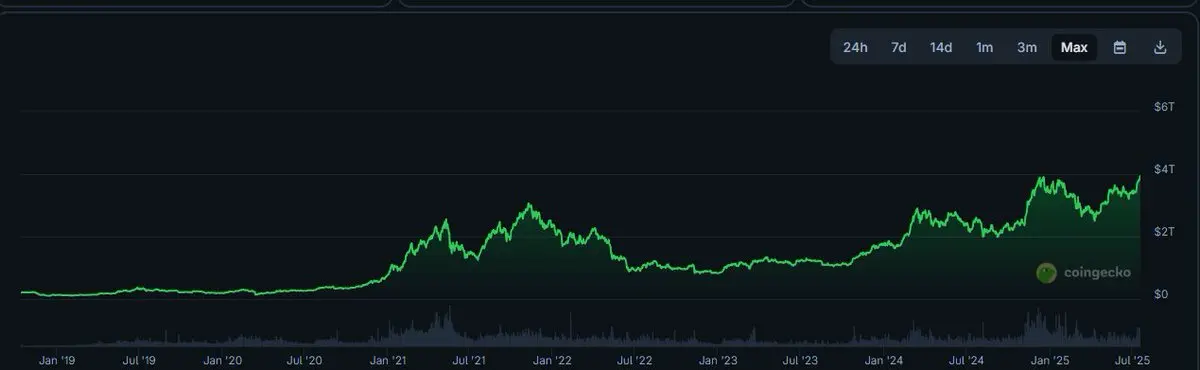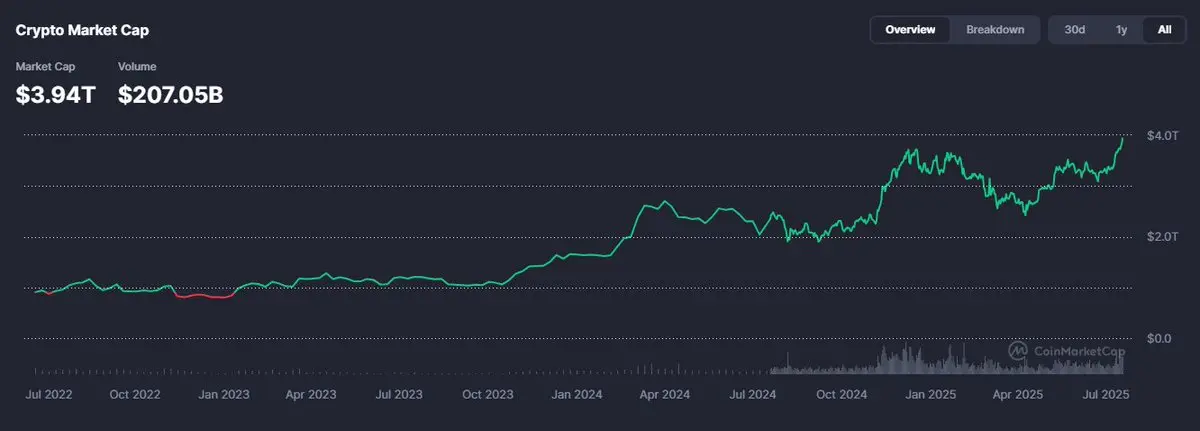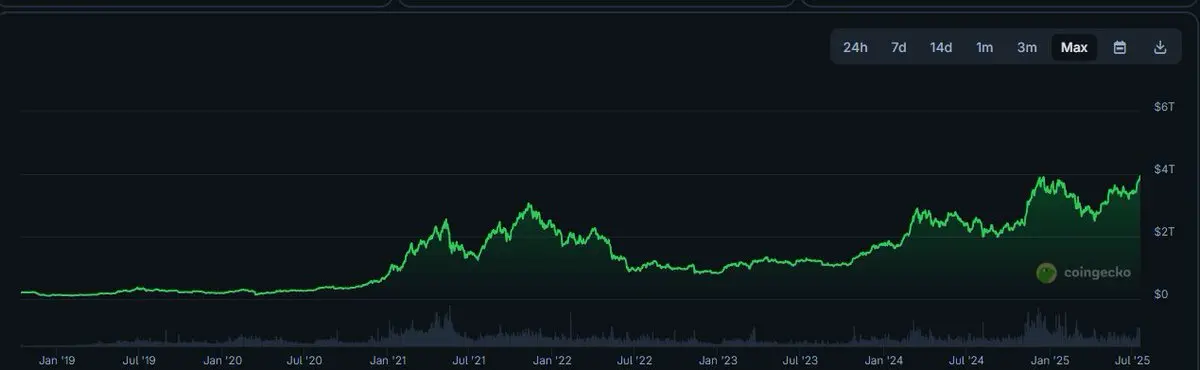
Après une nuit de travail avec le modèle local, le choix final est sorti :
1. Modèle principal : Qwen-30B-Instruct, il est suffisant pour un usage quotidien. (L'obéissance aux instructions est très bonne)
2. Inference de secours : j'ai gardé une version modifiée de 8 bits de GPT OSS mlx. La version 4 bits de GPT-OSS ne fonctionne pas très bien, et avoir un budget d'inférence au maximum dans les trois niveaux n'a pas beaucoup de sens.
3. coder toutes les directions, envisage de ne pas considérer les modèles locaux et d'utiliser directement le SOTA phare (après tout, on travaille quoi)
1. Modèle principal : Qwen-30B-Instruct, il est suffisant pour un usage quotidien. (L'obéissance aux instructions est très bonne)
2. Inference de secours : j'ai gardé une version modifiée de 8 bits de GPT OSS mlx. La version 4 bits de GPT-OSS ne fonctionne pas très bien, et avoir un budget d'inférence au maximum dans les trois niveaux n'a pas beaucoup de sens.
3. coder toutes les directions, envisage de ne pas considérer les modèles locaux et d'utiliser directement le SOTA phare (après tout, on travaille quoi)
GPT12.45%