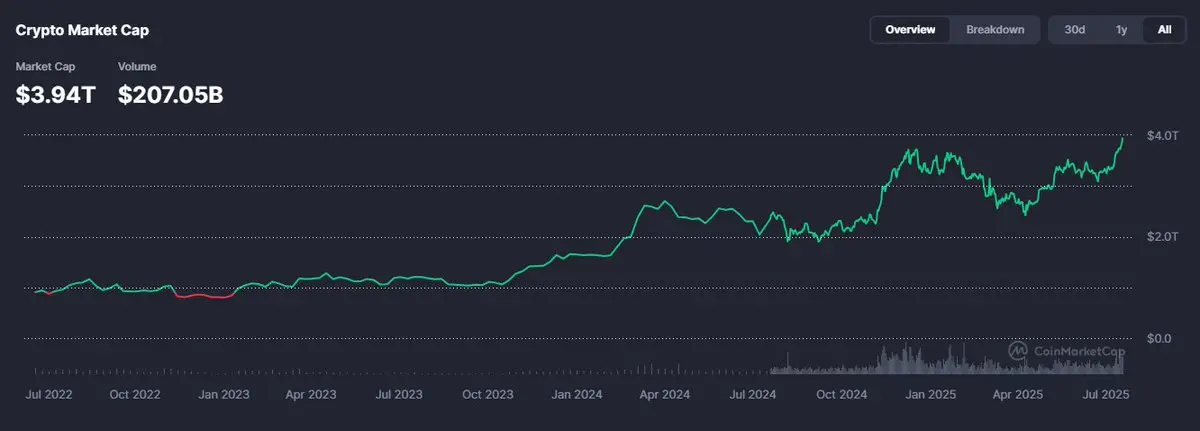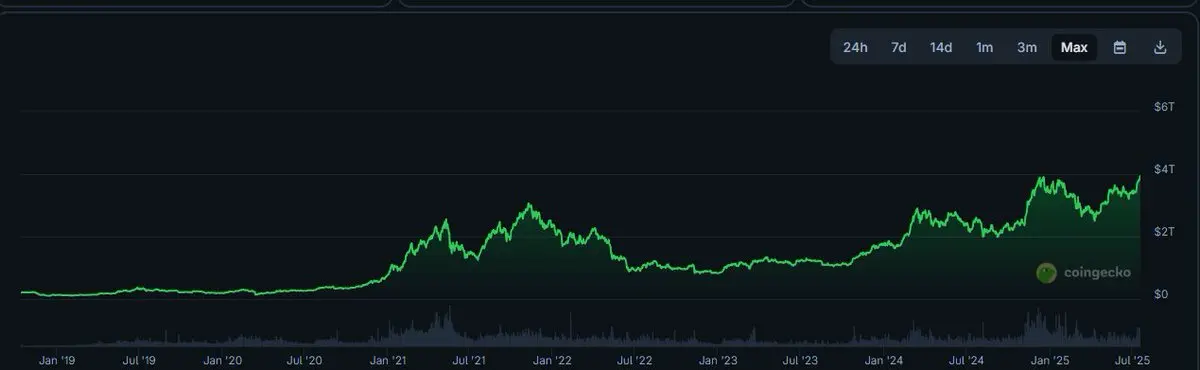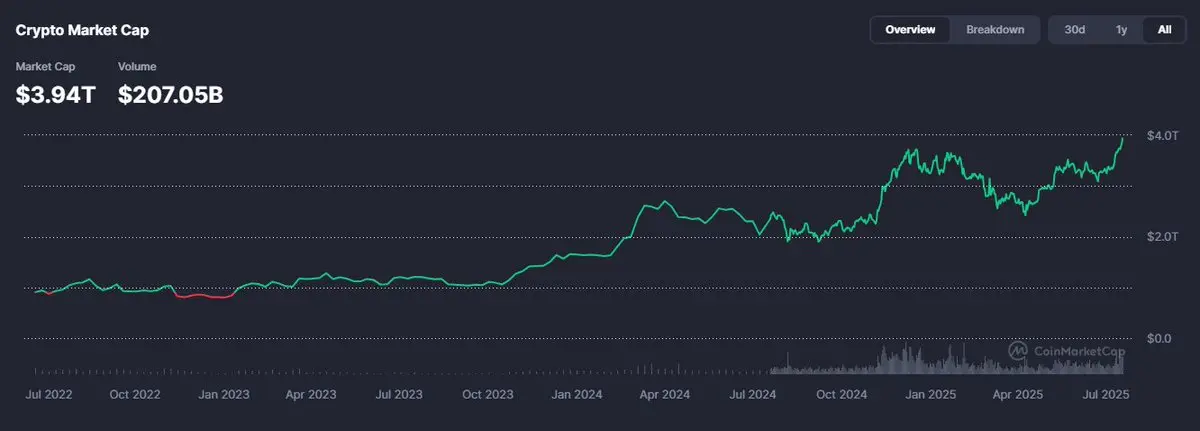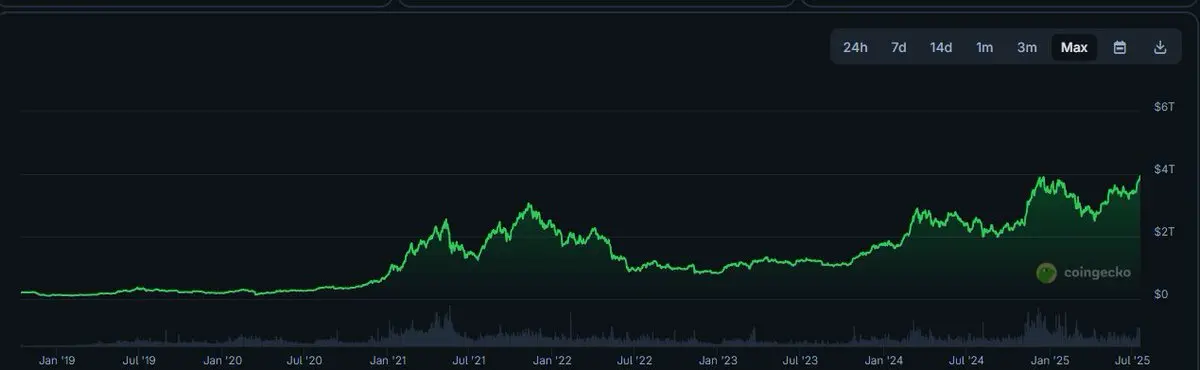
Локальная большая модель мучилась всю ночь, в конечном итоге выбрала результат:
1. Основная модель: Qwen-30B-Instruct, для повседневной работы этого достаточно. (Следование инструкциям очень хорошее)
2. Резервное выведение: оставили 8-битную модифицированную версию GPT OSS mlx. 4-битная версия GPT-OSS не очень хороша, увеличивать бюджет на вывод до трех уровней не имеет большого смысла.
3. coder все направления, планирует не рассматривать локальные модели и сразу использовать SOTA флагман (в конце концов, работа же)
1. Основная модель: Qwen-30B-Instruct, для повседневной работы этого достаточно. (Следование инструкциям очень хорошее)
2. Резервное выведение: оставили 8-битную модифицированную версию GPT OSS mlx. 4-битная версия GPT-OSS не очень хороша, увеличивать бюджет на вывод до трех уровней не имеет большого смысла.
3. coder все направления, планирует не рассматривать локальные модели и сразу использовать SOTA флагман (в конце концов, работа же)
GPT4.52%